普段の分析業務で最も簡単に扱える統計解析ツールとして、Excelにデフォルトで備わっている「データ分析ツール」について何回かに分けて解説していきます。
目次
分析ツール概要
まず、デフォルト状態では「データ分析ツール」が表示されていませんので有効化する必要がありますが、有効化の方法についてはいろんな方がWEB上に公開していますので、そちらをご覧ください。
※以下参照サイト例
http://excel-master.net/add-in/analysis-tool/
http://www.ipc.shimane- u.ac.jp/food/kobayasi/excelbunsekitool.htm
Excelの分析ツールの機能としては下記があります。
| No. | 種類 |
| 1 | 分散分析:一元配置 |
| 2 | 分散分析:繰り返しのある二元配置 |
| 3 | 分散分析:繰り返しのない二元配置 |
| 4 | 相関 |
| 5 | 共分散 |
| 6 | 基本統計量 |
| 7 | 指数平滑 |
| 8 | F検定:2標本を使った分散の検定 |
| 9 | フーリエ検定 |
| 10 | ヒストグラム |
| 11 | 移動平均 |
| 12 | 順位と百分位数 |
| 13 | 回帰分析 |
| 14 | サンプリング |
| 15 | t検定:一対の標本による平均の検定 |
| 16 | t検定:等分散を仮定した2標本による検定 |
| 17 | t検定:分散が等しくないと仮定した2標本による検定 |
| 18 | z検定:2標本による平均の検定 |
今回はこの中から、下記の2つについて説明します。
・サンプリング
・基本統計量
サンプリング
母集団とするデータ群からランダムでサンプリングを行う機能です。
データ抽出の仕方として、「指定周期による抽出」と「取得データ数指定による抽出」があります。
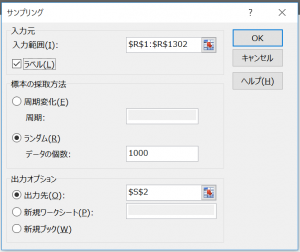
設定の流れとしては以下。
***************************************************************
1、「入力元 > 入力範囲」に母集団とするデータ群の範囲を指定。
※「ラベル」のチェックはデータの名称を定めたデータラベルが指定範囲に含められているかどうかを問うもの。
2、「標本の採取方法」から「周期変化」もしくは「ランダム」を選択。
→「周期変化」
データを取得する周期を指定。
例えば、「5」を指定した場合、データを5つおきに取得していく。
→「ランダム」
取得するデータ数を指定。指定された分データをランダムに取得する。
3、「出力オプション」にてサンプリングデータの出力先を指定。
***************************************************************
基本統計量
データ群の特徴・傾向を示す統計的な代表値と散布度を一括で取得する機能です。
尚、ここで指定するデータ群は標本データとしてみなされるため、算出される分散・標準偏差は不偏分散・標本標準偏差となります。
※基本統計量とは、母集団から得られた標本の特徴・傾向を示すもの。
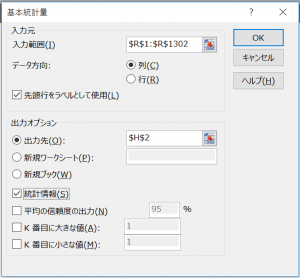
設定の流れとしては以下。
***************************************************************
1、「入力元 > 入力範囲」に基本統計量を取得したいデータ群の範囲を指定。
※「データ方向」は指定データ範囲が列(縦)方向に配置されているのか、行(横)方向に配置されているのかを指定。
※「先頭行をラベルとして使用」のチェックはデータの名称を定めたデータラベルが指定範囲に含められているかどうかを問うもの。
2、「出力オプション」にて算出データの出力先を指定。
3、出力データの詳細設定
→「統計情報」
平均値、標準誤差、中央値、最頻値、標準偏差、分散、尖度、歪度、データ範囲、
最小値、最大値、合計値、データ個数を取得。
→「平均の信頼度の出力」
平均値の信頼区間を出力するかどうかを指定。
※一般的には90%、95%、99%のいずれかで出力。
→「K番目に大きな値」
K番目に大きな値を出力するかどうかを指定。
→「K番目に小さな値」
K番目に小さな値を出力するかどうかを指定。
***************************************************************
また、実際の出力サンプルと各統計量の意味合いは下記となります。
| データ | ||
| 統計量 | 出力値 | 意味 |
| 平均 | 2032.91 | データの平均値。ここでは、相加平均(算術平均)。 ※Excel関数ではAVERAGE。 |
| 標準誤差 | 31.32822 | データのバラつき度合を示す値。標準偏差をデータ個数の平方根で割ったもので、値はデータ個数に左右される。 ※Excel関数では『STDEV.S÷SQRT(データ個数)』。 |
| 中央値 (メジアン) | 2037 | データの中央値。指定データの真ん中の値。データ個数が偶数の場合は真ん中の2つのデータ平均値。 ※Excel関数ではMEDIAN。 |
| 最頻値 (モード) | 207 | データの最頻値。指定データで最も頻度が高い値。 ※Excel関数ではMODE。 |
| 標準偏差 | 1129.989 | データのバラつき度合を示す値。ここでは、標本標準偏差。分散の平方根で、データ同士を比較する際に有用。 ※Excel関数ではSTDEV.S。 |
| 分散 | 1276876 | データのバラつき度合を示す値。ここでは、不偏分散。 ※Excel関数ではVAR.S。 |
| 尖度 | -1.222259 | データ分布のピークと裾が正規分布とどれだけ離れているかを示す値。正の値は鋭角、負の値は平坦を示す。尚、読み方は”せんど”。 ※Excel関数ではKURT。 |
| 歪度 | 0.018 | データ分布の非対称性の方向、及びその程度を示す値。正の値は右裾が長く、負の値は左裾が長いことを示す。尚、読み方は”わいど”。 ※Excel関数ではSKEW。 |
| 範囲 | 3894 | データの範囲。指定データの最小値から最大値までの距離。 ※Excel関数では『MAX-MIN』。 |
| 最小 | 102 | データの最小値。指定データで最も小さな値。 ※Excel関数ではMIN。 |
| 最大 | 3996 | データの最大値。指定データで最も大きな値。 ※Excel関数ではMAX。 |
| 合計 | 2644816 | データの合計値。 ※Excel関数ではSUM。 |
| データの個数 | 1301 | データの個数。 ※Excel関数ではCOUNT。 |
| 最大値(1) | 3996 | 指定データでK番目に大きな値。()内が指定したK番目を指す。 ※Excel関数ではLARGE。 |
| 最小値(1) | 102 | 指定データでK番目に小さな値。()内が指定したK番目を指す。 ※Excel関数ではSMALL。 |
| 信頼度(95.0%)(95.0%) | 61.4594 | 指定データの平均値の信頼区間。指定した有意水準における母集団の平均値が存在するであろう範囲を示す。 ※Excel関数ではCONFIDENCE。 |
以上、今回はここまでです。
最近のコメント